Statistics summary¶
This notebook is a brief introduction to various statistical analyses commonly used for amplicon data analysis - including some basic theory, links to more in-depth explanations, how to run them in R, and how to ensure the assumptions hold.
Getting more in-depth: Excellent introductions to various statistical concepts and analysis can be found in a Nature Methods collection of 2-page letters aimed at biologists.
The first paper, Importance of being uncertain, is a must read for anyone new to statistics.
# Load packages
library(ggplot2) # Plotting
Example datasets¶
mtcars: The data was extracted from the 1974 Motor Trend US magazine, and comprises fuel consumption and 10 aspects of automobile design and performance for 32 automobiles
data(mtcars)
pairedData: A data.frame with randomly generated paired data
# Set seed (for reproducibility when doing things that involves randomness)
set.seed(42)
# Set number of samples
nSamples <- 10
# Build data.frame with random measurements
pairedData <- data.frame(sampletime = c(rep("before", nSamples), rep("after", nSamples)),
subject = rep(LETTERS[1:nSamples], 2),
measurement = rnorm(nSamples * 2))
# Shuffle data.frame
pairedData <- pairedData[sample(1:nrow(pairedData)), ]
Two sample T-test ¶
The two-sample t-test is used for comparing the means of two samples; for example comparing a control condition with a treatment.
Assumptions¶
Samples are uncorrelated. This is the most crucial assumption: Samples should be independent. If the samples are paired, for example with before and after measurements, or in other ways correlated one-to-one, use the paired t-test.
Samples come from a population that have an approximately normal shape. It is quite robust to deviations, but will have higher chance of false positives/negatives with highly non-normal distributions. Transformations (e.g. log transform) can sometimes solve this problem.
Variance is equal in the two samples. The t-test is however robust to deviations from this assumption. In R the default t-test is the Welch variant, which solves the problem of unequal variances from unequal sample sizes.
In R¶
Let's compare the engine displacement of cars with automatic transmission (am = 1) compared to manual transmission (am = 0)
First plot boxplots:
ggplot(mtcars, aes(factor(am), disp)) + geom_boxplot()

Then run the t-test:
t.test(disp ~ am, data = mtcars)
We can see that the average displacement in cars with manual transmission (group 0) is 290, and in cars with automatic transmission (group 1) is 144. This difference is significant with a p-value of 0.00023. The difference between the two is between 75 and 218 (95% confidence interval)
Wilcoxon Rank Sum test ¶
The Wilcoxon Rank Sum test is used to compare the medians of two samples, similar to a two sample t-test. This test is however non-parametric and therefore has (almost) no assumptions on the distributions of the populations. It is less powerful than the t-test, especially for small (n<10) sample sizes.
Assumptions¶
Similar to the t-test, the samples should be uncorrelated and independent. A paired version of this test is the Wilcoxon Signed Rank test.
The two samples should come from populations with approximately similar shape.
In-depth paper on non-parametric tests
In R:¶
Let's compare the engine displacement of cars with automatic transmission (am = 1) compared to manual transmission (am = 0)
wilcox.test(disp ~ am, data = mtcars)
We can see that the average displacement in cars with manual transmission (group 0) is different than in cars with automatic transmission (group 1) a p-value of 0.0005493. The warnings tells us that some displacement values are similar, which means the p-value is an approximation. This is not problematic unless there are many ties.
Paired two sample tests ¶
If samples are paired, a paired test should be used. This should be used with for example before and after measurements on the same subjects. See the above two sections for assumptions.
In R it is crucial that the observations are in correct order, as the samples are paired according to the input order.
Ordering data in R¶
If we look at the dataset, we can see that it is not ordered according to the subject, as it should:
pairedData
Let's order it by subject:
pairedDataOrder <- pairedData[order(pairedData$subject), ]
pairedDataOrder
Paired t-test in R¶
before <- pairedDataOrder[pairedDataOrder$sampletime == "before", "measurement"]
after <- pairedDataOrder[pairedDataOrder$sampletime == "after", "measurement"]
t.test(after, before, paired = TRUE)
The average difference between before and after measurements is -0.71 (-2.21 to 0.79, 95% CI) and this is not statistically significant, p-value = 0.3107.
Also notice that we only have 9 degrees of freedom, despite having 20 observations in the input data.frame. This is because we have repeated measurements within subjects, and we actually only have 10 independent measurements. A paired t-test is therefore equivalent to finding the difference between before and after measuremnts and then running a one-sample t-test.
Let's try the same analysis with a one-sample t-test:
# Find the difference
difference <- after - before
difference
# One-sample t-test
t.test(difference, mu = 0)
This result is exactly identical to the paired two-sample test.
Correlation ¶
It is advised to read this excellent introduction on the difference between correlation, association, and causation.
As the above paper states: two variables are correlated when they display an increasing or decreasing trend
Correlation values range between 1 for perfect positive trend, 0 for no trend, to -1 for perfect negative trend. There are two types of correlation metrics that are typically used. Pearson's r and and Spearman's rho. Pearsons is used for linear trends. See collection of scatter plots and associated pearson correlations:
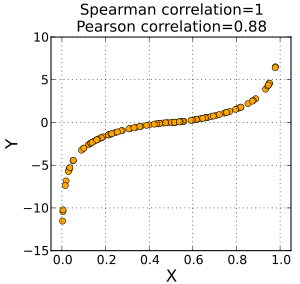
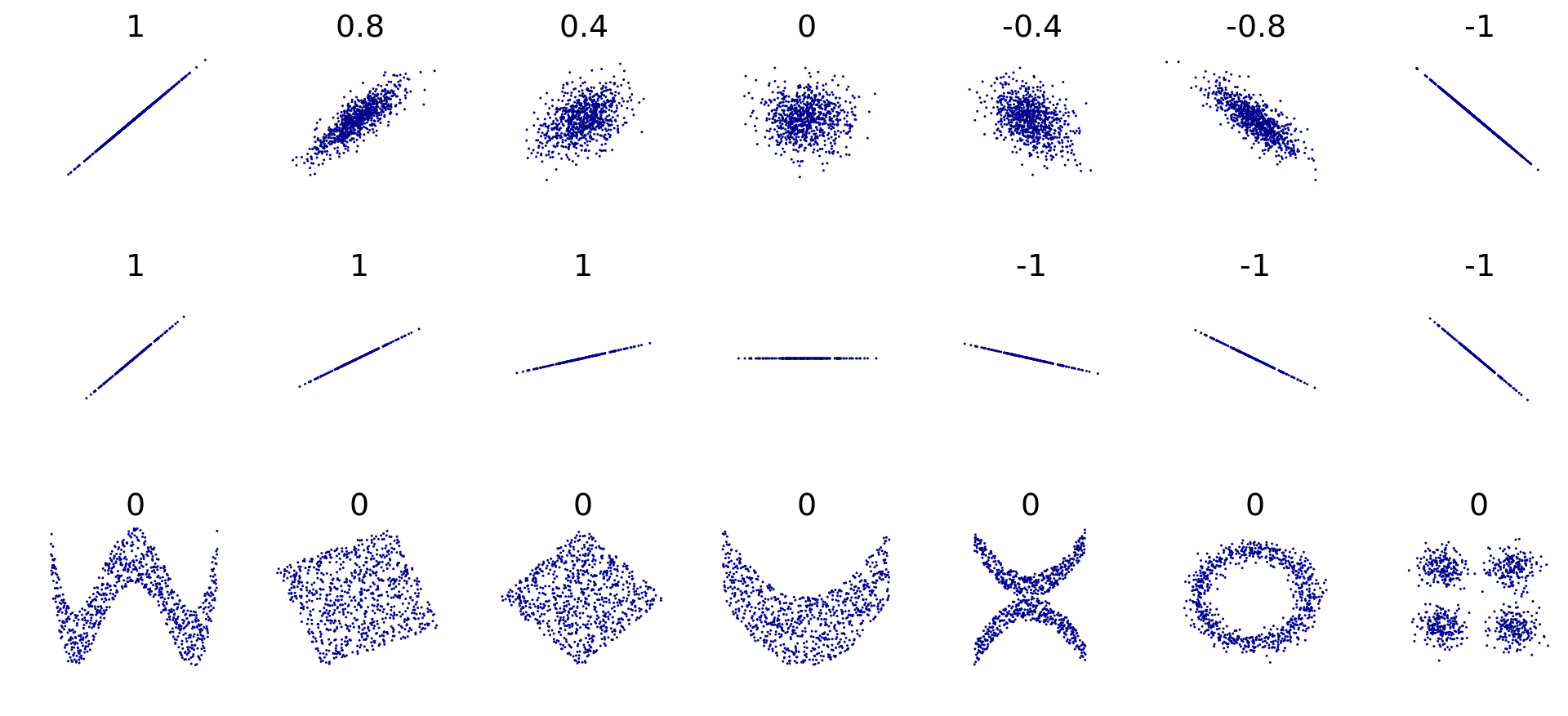 and Spearmans is used for monotonic trends. See the below graph from the Wikipedia page on Spearmans correlation:
and Spearmans is used for monotonic trends. See the below graph from the Wikipedia page on Spearmans correlation:
Assumptions¶
Pearsons assume linearity between variables and that both variables are (somewhat) normally distributed and homoscedastic. See this section for details.
Spearmans assumes a monotonic trend between variables. A non-monotonic trend is for example a U-shape or ∩-shape when plotting the two variables in a scatter plot as above.
In R:¶
Pearson's is calculated with the cor function. Here we find the correlation between horsepower and engine displacement from the car data:
cor(mtcars$disp, mtcars$hp)
The order of the variables does not matter:
cor(mtcars$hp, mtcars$disp)
Let's try the same with Spearman's correlation:
cor(mtcars$disp, mtcars$hp, method="spearman")
Spearman is basically a Pearson's correlation on ranked data:
cor(rank(mtcars$disp), rank(mtcars$hp))
Let's make a plot to visualize the trend between the two variables:
plot(mtcars$disp, mtcars$hp)

We can get p-values by using the cor.test function with the same input:
cor.test(mtcars$disp, mtcars$hp)
cor.test(mtcars$disp, mtcars$hp, method="spearman")
Linear regression ¶
In a simple linear regression we seek to find how changes in one continuous variable (X) impacts the estimation of another continuous variable (Y). In contrast to correlation, linear regression is asymmetrical, such that swapping X and Y will give a different result (the p-value would be the same however). It is based on the assumption that X is fixed (measured perfectly) and that Y is random (measured with error). Furthermore, it is based on the assumption that the residuals (distance between actual data points and the statistical model) are normally distributed. As with Pearsons correlation there is also an assumption of linearity and homoscedasticity.
In R:¶
Linear regression with engine displacement as indepedent (explanatory) variable and horsepower as dependent (response) variable.
# Save the model in the fit object
fit <- lm(hp ~ disp, data = mtcars)
# Get a summary of the model:
summary(fit)
The important output here are the coefficients and Adjusted R-squared (variance explained). There are two coefficients, one for the Intercept and one for the Y variable (disp). The Estimates are the estimated values of the coefficients. As such the model ($Y = a*X + b$) here is estimated as: $hp = 0.4375 * disp + 45.7345$.
This result seems to fit with the plot above (see the Correlation section).
The p-values (Pr(>|t|)) tests the hypothesis that the Estimate is zero. A low p-value therefore suggests that the Estimate is unlikely to be zero, given the assumptions of the linear regression. We can therefore see that the engine displacement is significantly associated with the horsepower. Also notice that the p-value is similar to the one from Pearson correlation. The adjusted R-squared tells us that our model explains 61.3% of the variance in the horsepower variable.
Check assumptions in R:¶
The easiest way to check the assumptions of a linear regression is to plot the fitted model. This produces four plots, which should be used to ensure that the assumptions hold.
par(mfrow=c(2,2)) # Plot in a 2x2 grid
plot(fit)

Residuals vs Fitted¶
This plot should be used to check for non-linearities in the residuals. The red line should be approximately linear. This is to ensure that there is not some hidden non-linearity that our model does not capture.
Normal Q-Q¶
This plot should be used to check for normality of residuals. The points should approximately follow the line. If you are unsure how it should look, you can simulate random normally distributed data to get a feel of it. Try to run the below several times with different samples sizes and check the output:
n_samples <- 20
residuals_simulated <- rnorm(n_samples)
qqnorm(residuals_simulated)
qqline(residuals_simulated)
Scale-Location¶
This plot should be used to check that residuals are homoscedastistic. The points should have an equal spread across the range of fitted values. If, for example, points were further from each other at high fitted values than lower fitted values, it could help re-running the model with a log-transformed response variable.
Residuals vs Leverage¶
This plot should be used to identify outliers. The Cook's distance (dotted lines) measures the impact of a data point on a model, specifically how much the predicted estiamte of y would change if the data point was omitted from the model. An outlier is a data point which has a substantially higher Cook's distance than most of the other observations. We can see that the data point with the Maserati Bora is maybe an outlier, but Cook's distances below 1 are usually not a problem.
If the above is unclear, details can be found in this article
ANOVA ¶
An ANOVA can be seen as an extension of a t-test. In the t-test you are only comparing two groups of samples. ANOVA is for variables with more than two groups.
Assumptions¶
Assumptions are as with the linear regression, and should be checked in a similar way.
In R:¶
Let's check if cars with different number of gears have different horsepower:
mtcars$gear <- as.factor(mtcars$gear)
# Define model
fit <- aov(hp ~ gear, data = mtcars)
# Get a summary of the model
summary(fit)
The number of gears seems to have an effect on the horsepower.
Note on as.factor()¶
We want to treat the 'gear' variable as categorical, which we tell R by converting it into a factor. This is crucial since this variable just consists of numbers (3, 4, or 5) and would by default therefore be treated as a continuous variable.
Multiple predictors in ANOVA¶
It is possible to add multiple predictors to ANOVA's (they can be added with +'s on the right-hand side of the formula). It important to note that the default ANOVA in R is using Type I Sums of Squares (SS), hence the order of the predictors will produce different results (unless the design is fully factorial). See this excellent blog for details on differences between Type I/II/III SS in ANOVA.
TukeyHSD post-hoc¶
We can run a TukeyHSD to get all pairwise comparisons
fitTukey <- TukeyHSD(fit)
fitTukey
Linear model ¶
A linear model is a general term which includes both linear regression and ANOVA. A linear regression is for continuous indepedent variables and ANOVA is for categorical independent variables. A linear model can be used for both, and a combination of both.
Assumptions¶
Assumptions are as with the linear regression, and should be checked in a similar way.
Furthermore, if there are more than one independent variable, they should not correlate strongly. Correlated predictors is called collinearity and can highly skew the results (See this paper for details)
In R:¶
Let's try to run the same model, as for the ANOVA above.
# Define model
fit <- lm(hp ~ gear, data = mtcars)
# Get a summary of the model
summary(fit)
The "gear" variable is split into so-called dummy variables. The first category (3 gears) is set as the Intercept, and we get estimates for the other categories (4 gears and 5 gears). The values next to "gear4" is the difference between the Intercept (3 gears) and the 4 gear category. The values next to "gear5" is the difference between the Intercept (3 gears) and the 5 gear category.
Pairwise comparisons¶
Similar to the ANOVA where we ran TukeyHSD, we can get comparisons between all pairs of categories for a linear model. For this we use the multcomp package:
library(multcomp)
summary(glht(fit, linfct=mcp(gear="Tukey")))
The results is similar to the TukeyHSD results from the ANOVA section
Multiple predictors¶
In the linear model, we can include multiple predictors (as long as they do not correlate too much with each other). It is important to stress that the estimate and p-value of a predictor can change depending on if/which other predictors are included in the model. A model should therefore be interepreted as a whole.
Let's include "disp" and "drat" in the above model
# Define model
fit <- lm(hp ~ gear + disp + drat, data = mtcars)
# Get a summary of the model
summary(fit)
We can check if we have problems with collinearity with the vif function from the car package. A rule of thump is that no vif should be above 5. The first column in the output "GVIF" should be used.
car::vif(fit)
We can run an ANOVA on this linear model, which will combine categorical predictors into one p-value:
anova(fit)
Homogeneity of variance ¶
It is an assumption of all linear models (including linear regression and ANOVA) and for Pearson's correlation that there is homogeneity of variance (also called homoscedasticity, as opposed to heteroscedasticity). This means that the spread (variance) of the data points should not have any association with the mean.
Let's try to simulate some heteroscedastic data to visualize the problem
# Simulate heteroscedastic data
set.seed(1)
df <- data.frame(Group = c(rep("A", 20), rep("B", 20), rep("C", 20)),
Value = c(rpois(20, 20), rpois(20, 100), rpois(20, 200)))
p <- ggplot(df, aes(Group, Value)) +
theme_bw() +
geom_point()
p

Let's try to run an ANOVA on the above data, and plot the diagnostics
fit <- aov(Value ~ Group, data = df)
plot(fit, which=1)

We can see that the spread is increasing as the fitted values increase. The p-values of this model will be highly biased. When variance increases with the mean, it often helps to log-transform the response variable. Let's try that:
fit_log <- aov(log10(Value) ~ Group, data = df)
plot(fit_log, which=1)

It helps somewhat, but partially creates the reverse problem; variance is higher with lower fitted values, but much better than the raw data.
Alternatively, one could use permutation, robust methods, or you could use another distibution than the normal ditribution. The details of these alternatives are beyond the scope of this notebook.